반응형
Decision Tree (결정트리)
- Tree를 만들기 위해 "예/아니오" 질문을 반복하여 학습하는 의사결정 모델
- 다양한 앙상블(ensemble)모델이 존재 (ex. RandomForest, GradientBoosting, XGBoost, LightGBM)
- 분류와 회귀에 모두 사용 가능
- 결정트리

- 새로운 데이터 포인트가 들어오면 해당하는 노드를 찾아,
분류라면 더 많은 클래스를 선택하고, 회귀라면 평균을 구한다 - 지니불순도를 사용하여 데이터 분류의 기준을 잡는다
- 타깃값이 하나로만 이루어진 리프노드를 순수노드(G=0)라고 한다
- 모든 노드가 순수노드가 될 때까지 학습하면, 모델이 복잡해지고 과대적합된다
Gini Impurity (지니 불순도)
: 데이터 집합의 불확실성 또는 순도를 수치화한 것
G값이 작을수록 순도가 높다
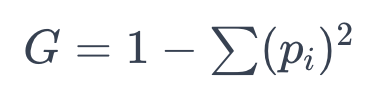
pi (특정 클래스에 속하는 항목의 비율)
- G=0 (p=1 데이터 집합이 완전히 순수, 하나의 데이터로만 이루어짐)
- G=0.5 (p1=0.5, p2=0.5 데이터 집합이 두개의 데이터로 이루어지고, 두 데이터의 개수가 같음)


Decision Tree(결정트리) 과대적합 제어
- 노드 생성을 미리 중단하는 사전 가지치기(pre-pruning)와 트리를 만든 후에 크기가 작은 노드를 삭제하는 사후 가지치기 (pruning)가 있다
(sklearn은 사전 가지치기만 지원) - 트리의 최대 깊이나 리프노드의 최대 개수를 제어
- 노드가 분할하기 위한 데이터포인트의 최소 개수를 지정
매개변수(Hyperparameter)
- max_depth : 트리의 최대 깊이 (값이 클수록 모델의 복잡도가 올라간다)
- max_leaf_nodes : 리프 노드의 최대 개수
- min_samples_leaf : 리프 노드가 되기 위한 최소 샘플의 개수
특징
장점
- 만들어진 모델을 쉽게 시각화할 수 있어, 이해하기쉽다 (white box model)
- 각 특성이 개별 처리되기때문에, 데이터 스케일에 영향을 받지않아 특성의 정규화나 표준화가 필요없다
- 트리 구성시, 각 특성의 중요도를 계산하기 때문에, 특성선택(Feature selection)에 활용될 수 있다
단점
- 훈련데이터 범위 밖의 포인트는 예측할 수 없다 (ex. 시계열 데이터)
- 가지치기를 사용함에도 불구하고 과대적합되는 경향이 있어 일반화 성능이 좋지않다
Decision Tree Ensemble (결정트리 앙상블)
- 앙상블은 여러 머신러닝 모델을 연결하여, 더 강력한 모델을 만드는 기법
- 결정트리의 가지치기 후, 과대적합되는 단점을 보완하는 모델
- Random Forest, Gradient Boosting, XGBoost, LightGBM, CatBoost 등
- 회귀와 분류에 모두 사용 가능

Random Forest
: 서로 다른 방향으로 과대적합된 트리를 많이 만들고, 평균은 내어 일반화시키는 모델
다양한 트리를 만드는 방법
- 트리를 만들 때, 사용하는 데이터 포인트 샘플을 무작위로 선택한다
- 노드 구성 시, 기준이 되는 특성을 무작위로 선택한다
매개변수
- n_estimators : 생성할 트리의 개수
- n개의 데이터 부트스트랩 샘플 구성 : n개의 데이터 포인트 중 무작위로 n횟수만큼 반복 추출, 중복된 데이터가 들어있을 수 있다
- max_features : 무작위로 선택될 후보 특성의 개수 (각 노드별로 max_features 개수만큼 무작위로 특성을 고른 뒤, 최선의 특성을 찾는다)
- max_feature를 높이면 트리들이 비슷해진다
특징
장점
- 결정트리의 단점을 보완하고 장점은 그대로 가지고있는 모델이어서 별다른 조정없이도 괜찮은 결과를 만들어낸다
- 트리가 여러개 만들어지기 때문에, 비전문가에게 예측과정을 보여주기 어렵다
- 랜덤하게 만들어지기 때문에, random_state를 고정해야 같은 결과를 볼 수 있다
단점
- 텍스트 데이터와 같은 희소한 데이터에는 잘 동작하지 않는다
- 큰 데이터세트에도 잘 동작하지만, 훈련과 예측이 상대적으로 느리다
- 트리 개수가 많아질수록 시간이 더 오래 걸린다
Gradient Boosting
: 정확도가 낮더라도 얕은 깊이의 모델을 만든 뒤, 나타난 예측오류를 두번째 모델이 보완
• 이전 트리의 예측오류를 보완하여, 다음 트리를 만드는 작업을 반복한다
• 마지막까지 성능을 쥐어짜고 싶은경우 사용 (주로, 경진대회에서 많이 활용)
* XGBoost model : GradientBoosting을 더 발전시킨 모델
매개변수
n_estimators : 생성할 트리의 개수 (트리가 많아질수록 과대적합이 될 수 있음)
learning_rate : 오차 보정 정도 (값이 높을수록 오차를 많이 보정)
max_depth : 트리의 깊이 (일반적으로 트리의 깊이를 깊게 설정하지 않음)
특징
| 장점 | 단점 |
| 보통 트리의 깊이를 깊게하지 않기 때문에, 예측속도가 비교적 빠르다. |
이전 트리의 오차를 반영해서 새로운 트리를 만들기 때문에, 학습 속도가 느리다. |
| 특성의 스케일을 조정하지 않아도 된다. | 희소한 고차원 데이터에는 잘 동작하지 않는다. |
반응형
'개발기록 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 지도학습 - Linear Classification 선형분류모델 (로지스틱회귀, SVM) (0) | 2024.11.23 |
|---|---|
| [머신러닝] 지도학습 (Supervised Learning) - Linear Model (Regression 회귀) (0) | 2024.11.19 |
| [머신러닝] 데이터 특징요소 분류 및 특징요소 추출 (Feature engineering) (0) | 2024.11.17 |
| 인공지능 (AI : Artificial Intelligence) (1) | 2024.11.14 |
| [머신러닝] 지도학습 (Supervised Learning) - KNN 알고리즘 (1) | 2024.10.06 |




댓글